1 머신러닝 과정
문제정의 : 프젝목적, 어떤 모델 만들지?, 지도학습 vs 비지도학습, 자료조사
데이터 수집
데이터 전처리 : 분석 전에 깔끔하게 만들어 줌(이상치 제거, 결측치 처리)
탐색적 데이터 분석 : 컬럼(변수)간의 관계확인, 기술통계량
모델 선택 및 학습
모델 예측 및 평가
모델을 가지고 서비스화(웹,앱)
2 목표
생존자/사망자 예측하는 모델을 만들어보자
머신러닝 모델 종류는 여러가지지만 tree모델 사용해보자
머신러닝 전체 과정을 체험해보자
kaggle 경진대회에 참여해서 순위를 확인해보자
3 데이터 수집
kaggle 사이트로부터 train, test, submission 다운로드
train : 학습 시키기 위한 데이터
test : 학습이 잘 됐는지 예측해보기 위한 데이터
submission : kaggle에 제출할 답안지
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 시각화 라이브러리(모듈)
import seaborn as sns # 시각화 라이브러리
test = pd.read_csv('./titanic/test.csv', index_col = 'PassengerId')
display(test.head()) # 본래 가지고 있는 형태를 그대로 출력
test.shape
# 생존/사망 여부의 컬럼이 없어서 열의 개수가 한개 적음
4 데이터 전처리 및 데이터 탐색
4.1 결측치 확인
train.info() # Age, Cabin, Embarked
test.info() # Age, Cabin, Fare
4.2 train-Embarked 결측치 처리(채우기)
# 사람들이 가장 많이 승선한 항을 찾아 결측치 값으로 처리
# train 기준으로 살펴보기 : 학습용 데이터 기준으로 살펴봐야함, 머신러닝 모델의 학습 영향을 주기때문
train['Embarked'].value_counts() #S
# 결측치가 있는 행 확인하는 작업
train[train['Embarked'].isnull()]
# 널값을 채워보자
# fillna('채울값') : 1. 결측치 찾기 2. 결측치 있으면 채우기
train['Embarked'] = train['Embarked'].fillna('S')
train[train['Embarked'].isnull()]
4.3 test - Fare 결측치처리(채우기)
# Fare 컬럼과 상관관계가 높은 컬럼을 기준으로 데이터를 살펴보기
# 그 컬럼에 관계해서 기술통계량 확인
# 평균값 확인
# 상관관계 확인하는 함수 : corr()
# 상관계수 출력
# -1 ~ +1 : -1,1 상관관계가 높음 / 0 상관관계가 낮음
train.corr()['Fare'].abs().sort_values(ascending = False)
# Pclass가 Fare 컬럼이랑 가장 상관관계가 높음
# Pclass, Fare 컬럼만 train에서 인덱싱해보기
train[['Pclass','Fare']].groupby('Pclass').mean()
# 성별 컬럼까지 연관해서 요금 평균 확인해보기
train[['Pclass','Fare','Sex']].groupby(['Pclass','Sex']).mean()
# test - Fare 결측치 있는 행 확인해보기
test[test['Fare'].isnull()]
# 값 채워보기
# 12.661633
test['Fare'] = test['Fare'].fillna(12.661633)
test.info()
4.4 Age 결측치 처리(채우기)
다른컬럼과의 상관관계를 확인 후 결측치를 채워보자
corr() 함수를 이용해보자
# train 기준으로 살펴보기
train.corr()['Age'].abs().sort_values(ascending=False)
# Pclass 컬럼이 상관관계가 가장 높음 -> 등급으로 그룹화하여 나이의 평균값 확인
gb1 = train[['Pclass','Age','Sex']].groupby(['Pclass','Sex']).mean()
gb1
# 멀티 인덱스 인덱싱
gb1.loc[(3,'female')]
# 1등급이고 남성인 데이터 접근해보기
gb1.loc[(1,'male')]
# train - Age 컬럼 결측치 행 모두 확인하기
train[train['Age'].isnull()]
# 데이터에 복잡한 처리를 하는 함수를 연결하는 기능(함수) : apply()
# 1. 사용자 정의 함수 : 복잡한 처리
# 2. 대상 데이터와 apply를 통해 연결
# 3. 처리가 완료된 데이터를 실제에 반영함(초기화)
def fill_age(row):
# row 행단위로 처리하게 만드는 함수
# 결측치가 있을때 처리하는 조건문
if np.isnan(row['Age']):
return gb1.loc[(row['Pclass'],row['Sex'])]
# 없으면 숫자값 그대로 반환하는 조건문
else :
return row['Age']
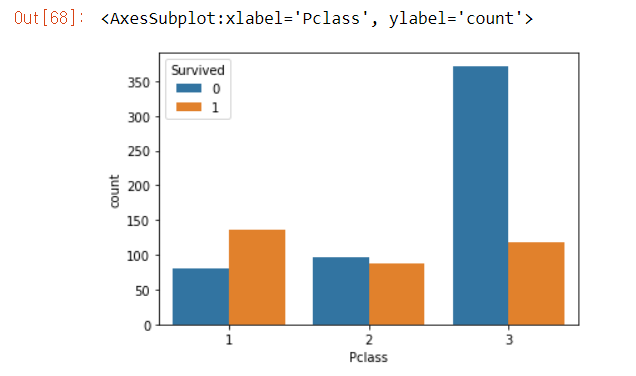
4.6.2 Pclass 시각화
승객 등급과 사망/생존의 관계 확인해보기
sns.countplot(data = train, x = 'Pclass', hue = 'Survived')
# 등급이 높을수록 생존율이 높음
4.6.3 Cabin과 Pclass 시각화
M층에서 왜 사람이 많이 죽었는지 확인해보기
등급과 연관이 있는 것인지 확인해보기
4.6.3 Cabin과 Pclass 시각화
M층에서 왜 사람이 많이 죽었는지 확인해보기
등급과 연관이 있는 것인지 확인해보기
sns.countplot(data = train, x = 'Cabin', hue = 'Pclass')
# M층에서 사망율이 높은 이유는 승객의 등급이 3등급인 사람이 많이 있었을 뿐
4.6.4 Sex, Embarked 시각화
# 성별이 사망/생존과 얼마나 연관이 있는지 확인
sns.countplot(data = train, x = 'Sex', hue = 'Survived')
# 승선항이 사망/생존과 얼마나 연관이 있는지 확인
sns.countplot(data = train, x = 'Embarked', hue = 'Survived')
4.6.5 수치형 데이터 시각화
Age 컬럼과 생존/사망 관계 확인하기
# 바이올린 플롯
plt.figure(figsize = (15,5))
sns.violinplot(data = train, x = 'Sex', y= 'Age', hue = 'Survived', split = True)
plt.ylim(0,80)
# 남자아이일 경우에 생존율이 높음
# 여자아이일 경우에 사망율이 높음
train['Age'].describe() # 기술하다, 설명하다
4.6.6 Fare 시각화
# Fare 요금의 기술통계량 확인해보기!
train['Fare'].describe()
# 일반적인 사람들은 중앙값(대푯값) 기준으로 14정도 내고 승선했을 것이다!
# 평균이 대표가 도리 수 없는 이유 512라는 큰 값의 영향을 받았을 수 있기 때문